
Hello Everyone,
I'm planning to develop reliability and maintainability study for data centers since it is required by the client. My method of developing this study is by using fault tree analysis. However, I am stuck with the fundamentals of Boolean algebra and not quite sure which approach to use. Below is an example
Assuming there are 2 redundant system, let's call them System 1 and System 2. These 2no. systems both have components A, B and C. These components are assumed to be identical for both System 1 and System 2 (A1, B1, C1 for System 1 and A2, B2, C2 for System 2).
Diagram below shows the approach I have used.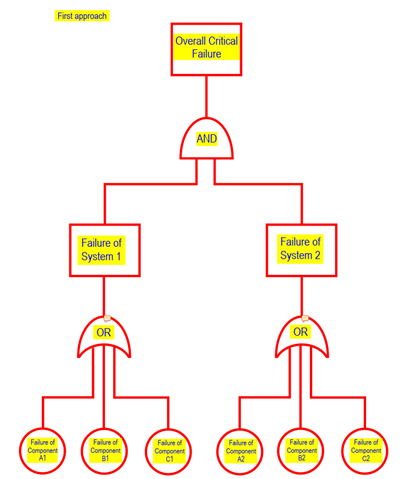
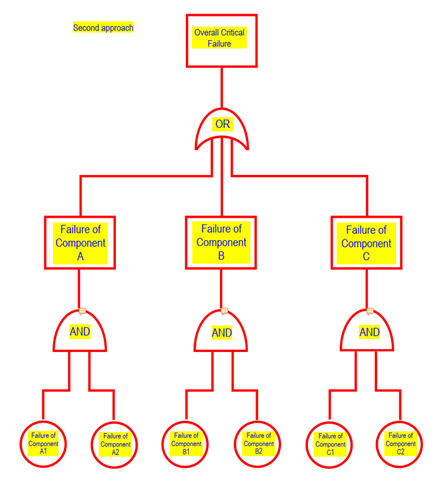
Which of the following fault tree above is the more appropriate representation of overall critical failure?
Regards,

