
1. Introduction
The rapid evolution of AI models has led to significant advancements in various domains, including mathematical problem-solving and coding. This article presents a comparative analysis of benchmark results from recent AI models, focusing on their strengths and limitations across multiple evaluation criteria. The models analyzed include:
- DeepSeek-R1
- OpenAI-o1-1217
- DeepSeek-R1-32B
- OpenAI-o1-mini
- DeepSeek-V3
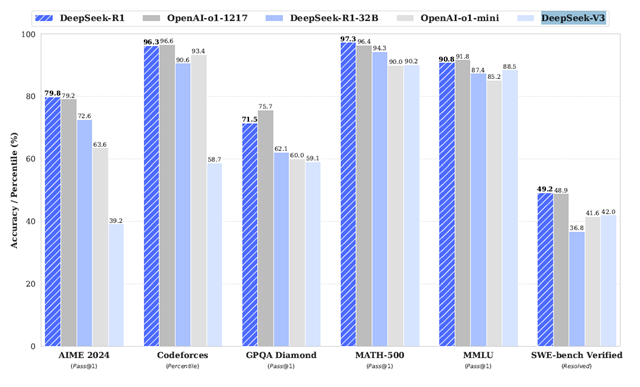
Figure 1: Benchmark performance of DeepSeek-R1 vs. OpenAI and other AI models in math and coding tasks. (As per the ref 1)
This analysis provides valuable insights into the performance of these models in different tasks, highlighting their respective capabilities and areas for improvement.
2. Benchmark Performance Overview
As per reference 1, Each bar in the benchmark chart represents how well a model performed in a specific test, with taller bars indicating better accuracy. The tests measure various cognitive and computational abilities:
- AIME 2024 – Solving mathematical problems.
- Codeforces – Competitive programming and problem-solving.
- GPQA Diamond – Answering complex questions.
- MATH-500 – Advanced mathematical problem-solving.
- MMLU – Multidisciplinary understanding and reasoning.
- SWE-bench Verified – Software engineering tasks.
Key Findings
- DeepSeek-R1 (blue striped bars) excels in most tests, particularly in mathematics-related tasks such as MATH-500 and MMLU.
- DeepSeek-R1-32B (solid blue bars) and OpenAI-o1-1217 (grey bars) also demonstrate strong performance but fall slightly short of DeepSeek-R1 in some categories.
- OpenAI-o1-mini (light grey bars) and DeepSeek-V3 (light blue bars) exhibit lower scores across most tests, indicating relative weaknesses in these tasks.
- Software engineering tasks (SWE-bench Verified) present a challenge for all models, as they perform lower in this category than in others, suggesting that AI models still struggle with complex software verification.
3. Math and Coding Performance Comparison
Reference (2) provides a tabular representation of accuracy and success rates, with higher numbers indicating superior performance.
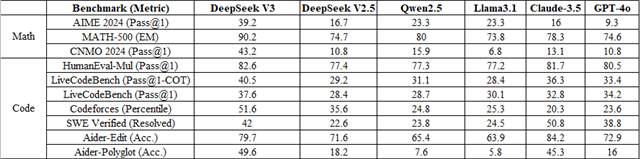
Figure 2: Comparison of AI models, including DeepSeek V3, GPT-4o, and Claude-3.5, on math and coding benchmarks.(As per the ref 2)
Mathematical Problem-Solving
- DeepSeek V3 emerges as the best model for solving mathematical problems, achieving the highest scores in MATH-500 (90.2%) and HumanEval-Mul (82.6%).
- GPT-4o and Claude-3.5 also perform well in mathematics but rank slightly lower than DeepSeek V3.
- DeepSeek V2.5 and Qwen2.5 score lower in most mathematical evaluations, indicating difficulties with complex problem-solving.
Coding Performance
- Claude-3.5 leads in code editing (Aider-Edit 84.2%) and software verification (SWE Verified 50.8%).
- DeepSeek V3 is particularly strong in competitive programming, achieving the highest Codeforces score (51.6%).
- GPT-4o and Llama3.1 perform moderately well in coding tasks but are not the top-performing models in this area.
- DeepSeek V2.5 and Qwen2.5 show weaker results in coding compared to other models.
4. Conclusion
This comparative analysis highlights the significant advancements in AI models, particularly in mathematical problem-solving and programming. While DeepSeek V3 dominates in mathematics, Claude-3.5 leads in software-related tasks. However, challenges remain in software verification, indicating room for further AI development in this domain.
These findings emphasize the growing specialization of AI models, with some excelling in problem-solving while others perform better in practical coding tasks. Future improvements should focus on enhancing AI capabilities in software engineering and multidisciplinary reasoning to create more well-rounded, efficient models.
By understanding these benchmark performances, researchers and developers can make informed decisions on selecting the most suitable AI models for specific applications, whether in academia, industry, or real-world problem-solving.
This analysis presents a comparative evaluation of recent AI models based on their performance in math and coding benchmarks. The findings are derived from the benchmark results presented in the two referenced studies, [Reference (1)] and [Reference (2)]. It is important to note that this is purely a comparison based on these sources, and actual performance may vary depending on specific tasks and real-world applications.
4. References
[1] DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, et al., "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning," arXiv:2501.12948 [cs.CL], 2025. Available: https://doi.org/10.48550/arXiv.2501.12948.
[2] DeepSeek-AI, "DeepSeek V3 Model Performance Benchmarks," Available: https://www.deepseek.com. Accessed: Feb. 2025.