
Introduction
The global economy is fuelled by knowledge and information, the digital sector growing 6x faster than the economy as a whole. AI will act as a further accelerant in boosting the economy and has the potential of being transformative across many sectors.

Figure 1 GenAI has wide application
However, in realising this promise, GenAI faces a number of challenges: 1) foundational LLMs have a great set of skills and generalist knowledge, but know nothing about individual companies’ products & services; 2) whilst LLMs are great at providing an instant answer, they often misunderstand the question or simply hallucinate in their response; equally, 3) LLMs need to improve in their reasoning capabilities to understand and solve complex problems; and finally, 4) LLMs are compute intensive, inhibiting their widespread adoption.
This article looks at how these challenges are being addressed.
Tailoring LLMs
Fine-tuning
First and foremost, LLMs need customisation to understand company data & processes and best deliver on the task at hand. Pre-training, in which a company develops its own LLM trained on their data might seem like the obvious choice but is not easy, requiring massive amounts of data, expensive compute, and a dedicated team.
Figure 2 LLM pre-training
A simpler approach takes an existing foundational model and fine-tunes it by adapting its parameters to obtain the knowledge, skills and behaviour needed.
Figure 3 LLM fine-tuning
Fine-tuning though updates all the parameters, so can quickly become costly and slow if adapting a large LLM, and keeping it current will probably require re-tuning on a regular basis. Parameter-efficient fine-tuning (PEFT) techniques such as Low-rank Adaptation (LoRA) address this issue by targeting a subset of the parameters, speeding up the process and reducing cost.
Rather than fine-tuning the model, an alternate is to provide guidance within the prompt, an approach known as in-context learning.
In-context Learning
Typically, LLMs are prompted in a zero-shot manner:

Figure 4 Zero-shot prompting [source: https://www.oreilly.com]
LLMs do surprisingly well when prompted in this way, but perform much better if provided with more guidance via a few input/output examples:

Figure 5 Few-shot ICL [source: https://www.oreilly.com]
As is often the case with LLMs, more examples tends to improve performance, but not always - irrelevant material included in the prompt can drastically deteriorate the LLM's performance. In addition, many LLMs pay most attention to the beginning and end of their context leaving everything else “lost in the middle”.
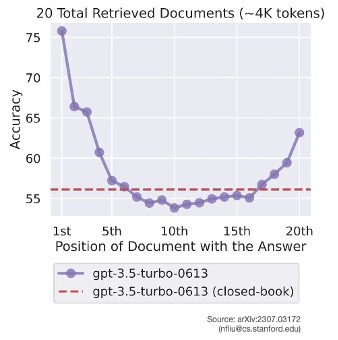
Figure 6 Accuracy doesn’t scale with ICL volume
In-context learning neatly side-steps the effort of fine-tuning but results in lengthier prompts which increases compute and cost; a few-shot PEFT approach may produce better results, and be cheaper in the long run.
Whilst fine-tuning and in-context learning hones the LLM’s skills to particular tasks, it doesn’t acquire new knowledge. For tasks such as answering customer queries on a company's products and services, the LLM needs to be provided with supplementary knowledge at runtime. Retrieval-Augmented Generation (RAG) is one such mechanism for doing that.
Retrieval-Augmented Generation (RAG)
The RAG approach introduces a knowledge store from which relevant text chunks can be retrieved and appended to the prompt fed into the LLM. A keyword search would suffice, but it's much better to retrieve information based on vector similarity via the use of embeddings:
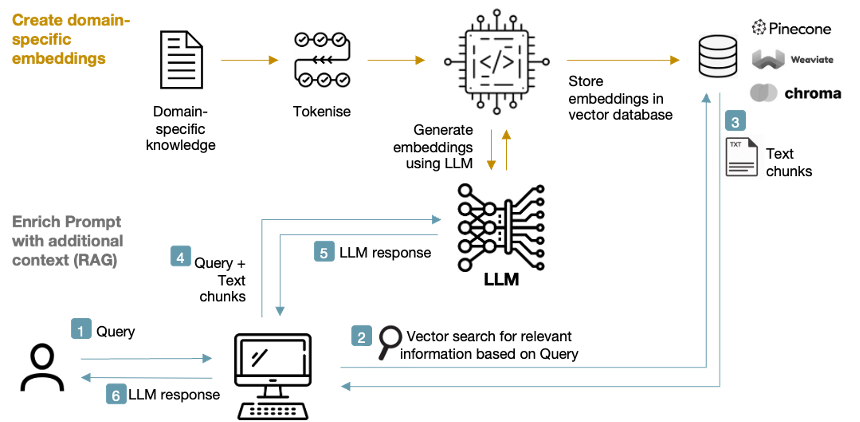
Figure 7 RAG system
RAG boosts the knowledge available to the LLM (hence reducing hallucinations), prevents the LLM’s knowledge becoming stale, and also gives access to the source for fact-checking.
RAPTOR goes one step further by summarising the retrieved text chunks at different abstraction levels to fit the target LLM’s maximum context length (or to fit within a given token budget), whilst Graph RAG uses a graph database to provide contextual information to the LLM on the retrieved text chunk thus enabling deeper insights.
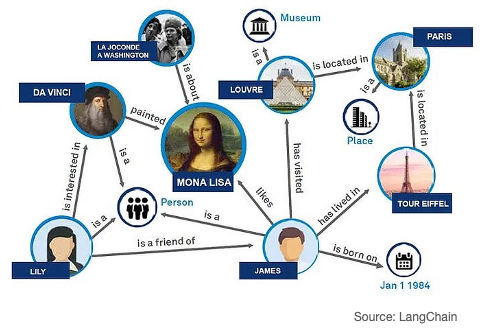
Figure 8 GraphRAG
Small Language Models (SLMs)
Foundational LLMs incorporate a broad set of skills but their sheer size precludes them from being run locally on devices such as laptops and phones. For singular tasks, such as being able to summarise a pdf, or proof-read an essay, a Small Language Model (SLM) that has been specially trained for the task will often suffice. Microsoft’s Phi-3, for example, has demonstrated impressive capabilities in a 3.8B parameter model small enough to fit on a smartphone. The recently announced Copilot+ PCs will include a number of these SLMs, each capable of performing different functions to aid the user.

Figure 9 Microsoft SLM Phi-3
Apple have also adopted the SLM approach to host LLMs on Macs and iPhones, but interestingly have combined the SLM with different sets of LoRA weights loaded on-demand to adapt it to different tasks rather than needing to deploy separate models. Combined with parameter quantisation, they’ve squeezed the performance of an LLM across a range of tasks into an iPhone 15 Pro whilst still generating an impressive 30 tokens/s output speed.
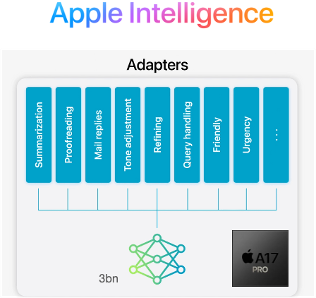
Figure 10 Apple Intelligence
Reasoning
Whilst LLMs are surprisingly good across a range of tasks, they still struggle with reasoning and navigating complex problems.
Using the cognitive model devised by the late Daniel Kahneman, LLMs today arguably resemble the Fast-Thinking system, and especially so in zero-shot mode, trying to produce an instant response, and often getting it wrong. For AI to be truly intelligent, it needs to improve its Slow Thinking and reasoning capabilities.
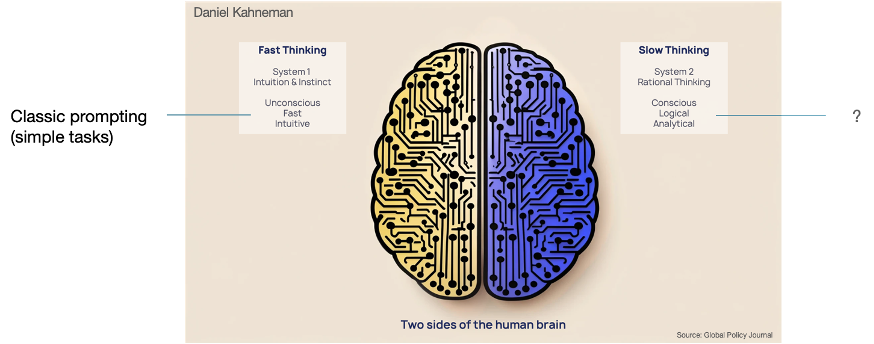
Figure 11 Daniel Kahneman’s cognitive system model
Instruction prompting
Experimentation has found, rather surprisingly, that including simple instructions in the prompt can encourage the LLM to take a more measured approach in producing its answer.
Chain of Thought (CoT) is one such technique in which the model is instructed with a phrase such as “Let’s consider step by step…” to encourage it to break down the task into steps, whilst adding a simple “be concise” instruction can shorten responses by 50% with minimal impact on accuracy. Tree of Thoughts (ToT) is a similar technique, but goes further by allowing multiple reasoning paths to be explored in turn before settling on a final answer.
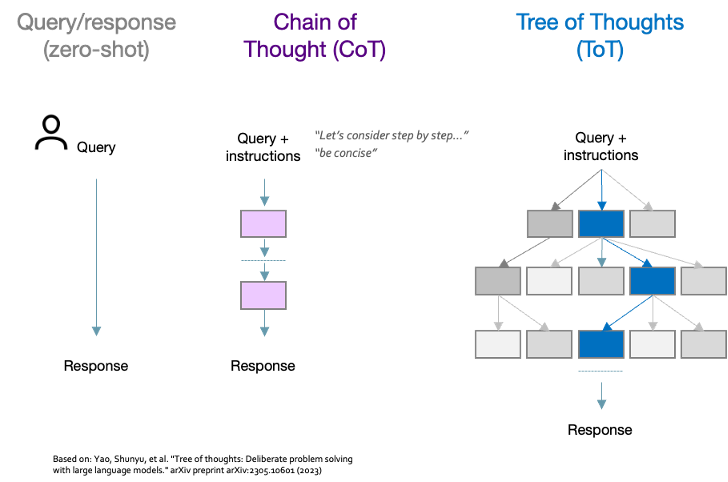
Figure 12 CoT and ToT instruction prompting
Self-ask goes further still by asking the model to break down the input query into sub-questions and answer each of these first (and with the option of retrieving up-to-date information from external sources), before using this knowledge to compile the final answer - essentially a combination of CoT and RAG.

Figure 13 Self-ask instruction prompting
Agentic systems
Agentic systems combine the various planning & knowledge-retrieval techniques outlined so far with additional capabilities for handling more complex tasks. Most importantly, agentic systems examine their own work and identify ways to improve it, rather than simply generating output in a single pass. This self-reflection is further enhanced by giving the AI Agent tools to evaluate its output, such as running the code through unit tests to check for correctness, style, and efficiency, and then refining accordingly.
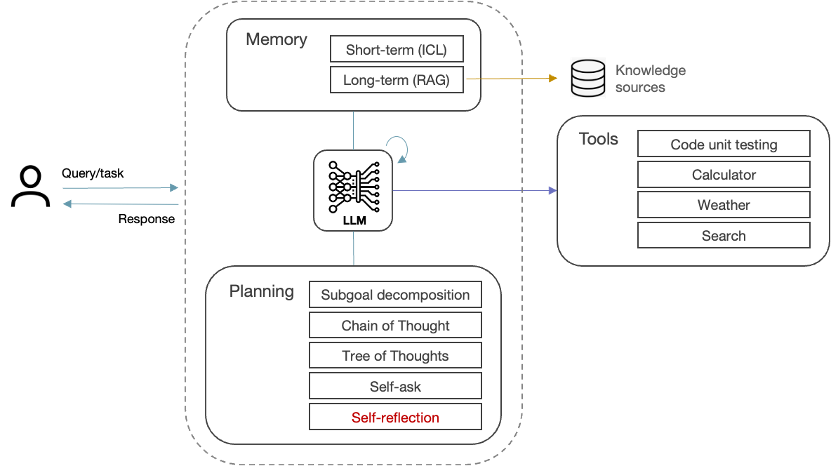
Figure 14 Agentic system
More sophisticated agentic workflows might separate the data gathering, reasoning and action taking components across multiple agents that act autonomously and work collaboratively to complete the task. Some tasks might even be farmed out to multiple agents to see which comes back with the best outcome; a process known as response diversity.
Compared to the usual zero shot approach, agentic workflows have demonstrated significant increases in performance - an agentic workflow using the older GPT-3.5 model (or perhaps one of the SLMs mentioned earlier) can outperform a much larger and sophisticated model such as GPT-4.
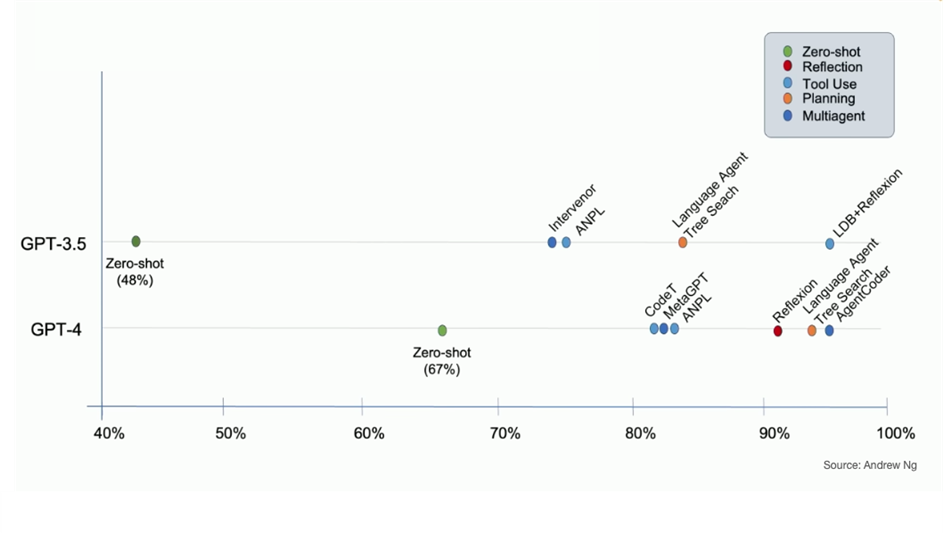
Figure 15 Agentic system performance
It's still early days though, and there remain a number of areas that need further optimisation. LLM context length, for instance, can place limits on the amount of historical information, detailed instructions, input from other agents, and own self-reflection that can be accommodated in the reasoning process. Separately, the iterative nature of agentic workflows can result in cascading errors, hence requiring intermediate quality control steps to monitor and rectify errors as they happen.
Takeaways
LLMs burst onto the scene in 2022 with impressive fast-thinking capabilities albeit plagued with hallucinations and knowledge constraints. Hallucinations remain an area not fully solved, but progress in other areas has been rapid: expanding the capabilities with multi-modality, addressing the knowledge constraints with RAG, and integrating LLMs at an application and device level via CoPilot, CoPilot+ PCs & Apple Intelligence using SLMs and LoRA.
2024 will likely see agentic workflows driving massive progress in automation, and LLMs gradually improving their capabilities in slow-thinking for complex problem solving.
And after that? Who knows, but as the futurologist Roy Amara sagely pointed out, “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run”… so let’s see.
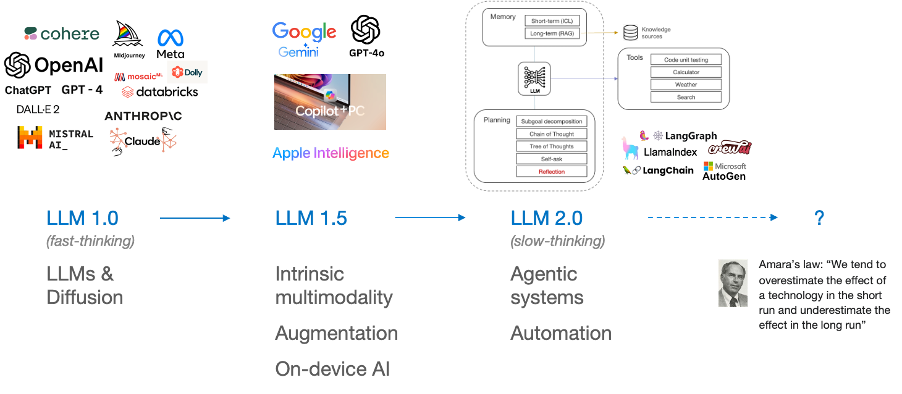
Figure 16 LLM evolution

