Hi everyone,
I’m new to the EngX community and looking forward to learning from you all. I’d like to start a conversation about something I think many of us face and that is updating legacy control systems in power plants and other critical infrastructure, especially when it comes to growing OT cyber threats.
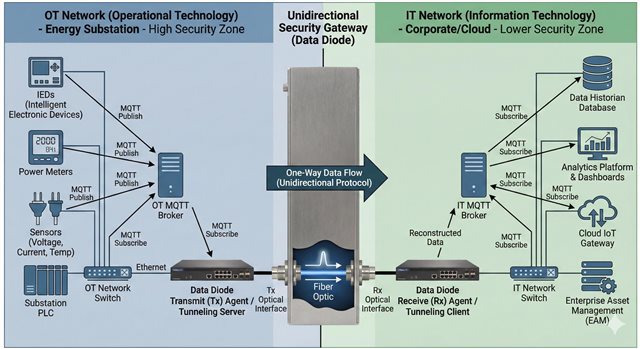
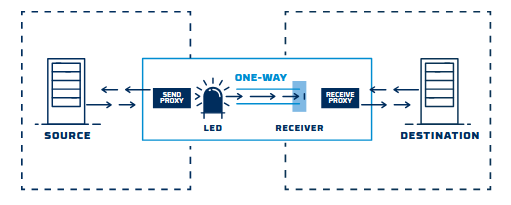
Lot of these systems were designed decades ago, with reliability in mind but little thought given to cybersecurity. Today, they’re exposed to new risks that weren’t imagined back then. The challenge is finding a way to retrofit these systems efficiently and without tearing everything apart or causing long periods of downtime.
In the UK, where our energy and infrastructure systems are heavily relied upon, even a small disruption can create big problems. So how do we make these updates both secure and practical?
I’m particularly interested in hearing how others have approached efficient retrofitting and what worked, what didn’t, and how you balanced the iron triangle of cost, time, quality and scope. Are there certain strategies or tools that helped modernize your systems without overhauling them completely.
Would love to hear your thoughts and experiences.
Thanks,
Taimur | MIET